I am a research scientist at the Robotics and AI Institute in Zurich. I previously worked as a research scientist at Technical University of Nuremberg and researched on scene representation and vision language action models. I did my PhD at University of Freiburg supervised by Prof. Wolfram Burgard. Previously I obtained my Master’s Degree from Technical University of Munich, majoring in Robotics, Cognition, Intelligence. During my Master’s study, I was lucky to be able to exchange to ETH, Zurich for two semesters and do research on visual-lidar fusion for mapping. Earlier, I got my Bachelor’s Degree on Vehicle Engineering from Jilin University in China. Currently, my research interests lie in scene representation for robot applications (like open-vocabulary mapping, especially in dynamic scenes), vision language action models for robot navigation and manipulation, and 3D-LLM.
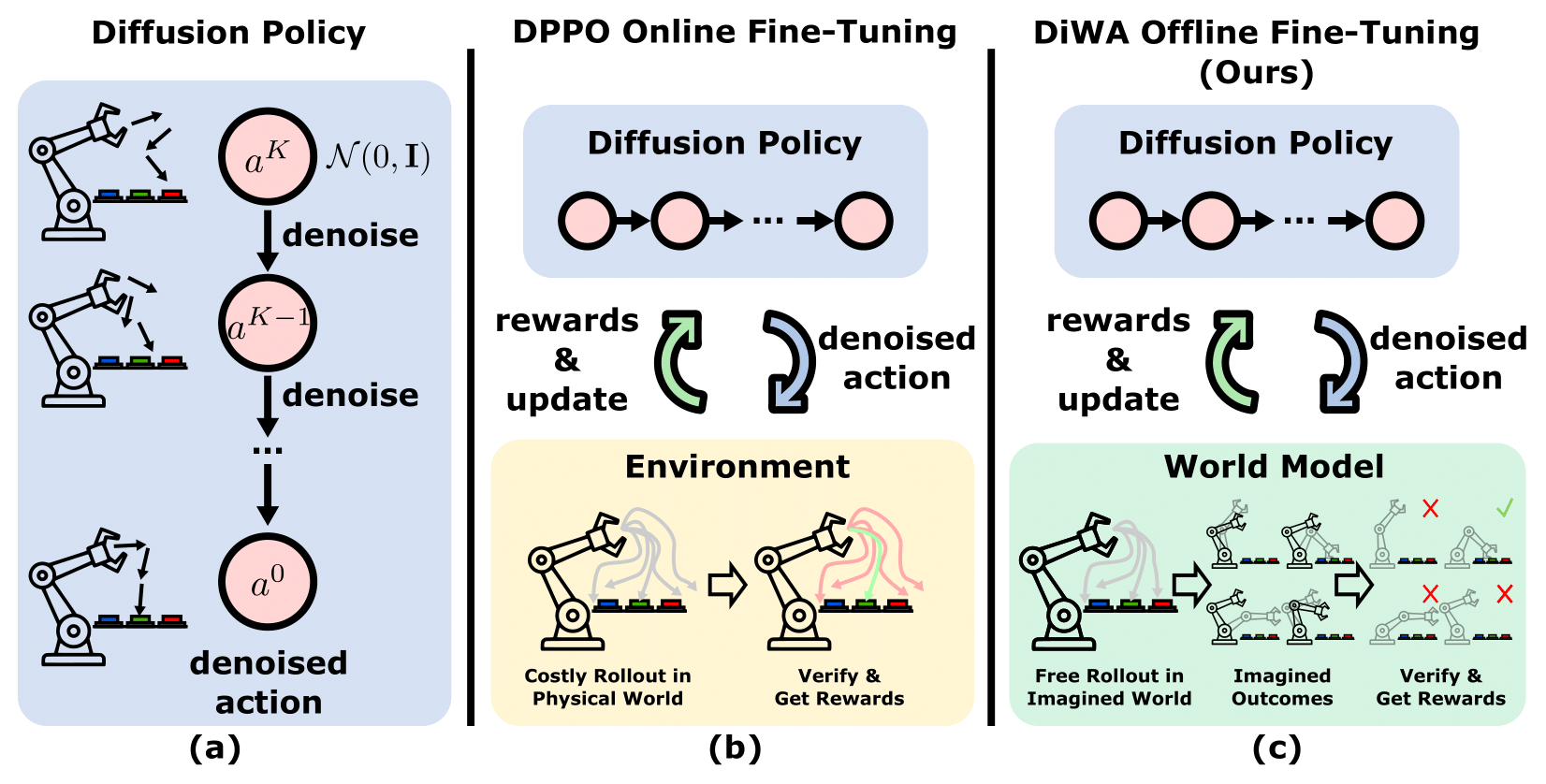
@inproceedings{chandra2025diwa,title={Diffusion Policy Adaptation with World Models},author={Chandra, Akshay L and Nematollahi, Iman and Huang, Chenguang and Welschehold, Tim and Burgard, Wolfram and Valada, Abhinav},booktitle={Proc.~of the Conference on Robot Learning (CoRL)},year={2025},}
Articulated Object Estimation in the Wild
Abdelrhman Werby*, Martin Büchner*, Adrian Röfer*, Chenguang Huang, Wolfram Burgard, and 1 more author
In Proc. of the Conference on Robot Learning (CoRL), 2025
@inproceedings{werby2025arti4d,title={Articulated Object Estimation in the Wild},author={Werby, Abdelrhman and Büchner, Martin and Röfer, Adrian and Huang, Chenguang and Burgard, Wolfram and Valada, Abhinav},booktitle={Proc.~of the Conference on Robot Learning (CoRL)},year={2025},}
Multimodal Spatial Language Maps for Robot Navigation and Manipulation
Chenguang Huang, Oier Mees, Andy Zeng, and Wolfram Burgard
@article{huang23multimodal,title={Multimodal Spatial Language Maps for Robot Navigation and Manipulation},author={Huang, Chenguang and Mees, Oier and Zeng, Andy and Burgard, Wolfram},journal={International Journal of Robotics Research},year={2025},}
BYE: Build Your Encoder with One Sequence of Exploration Data for Long-Term Dynamic Scene Understanding
Chenguang Huang, Shengchao Yan, and Wolfram Burgard
@article{huang2025bye,author={Huang, Chenguang and Yan, Shengchao and Burgard, Wolfram},journal={IEEE Robotics and Automation Letters},title={BYE: Build Your Encoder with One Sequence of Exploration Data for Long-Term Dynamic Scene Understanding},year={2025},}
2024
Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration
Abby O’Neill, Abdul Rehman, Abhiram Maddukuri, Abhishek Gupta, Abhishek Padalkar, and 274 more authors
In Proc. of the IEEE International Conference on Robotics & Automation (ICRA), 2024
@inproceedings{o2024openx,title={Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration},author={O'Neill, Abby and Rehman, Abdul and Maddukuri, Abhiram and Gupta, Abhishek and Padalkar, Abhishek and Lee, Abraham and Pooley, Acorn and Gupta, Agrim and Mandlekar, Ajay and Jain, Ajinkya and Tung, Albert and Bewley, Alex and Herzog, Alex and Irpan, Alex and Khazatsky, Alexander and Rai, Anant and Gupta, Anchit and Wang, Andrew and Singh, Anikait and Garg, Animesh and Kembhavi, Aniruddha and Xie, Annie and Brohan, Anthony and Raffin, Antonin and Sharma, Archit and Yavary, Arefeh and Jain, Arhan and Balakrishna, Ashwin and Wahid, Ayzaan and Burgess-Limerick, Ben and Kim, Beomjoon and Schölkopf, Bernhard and Wulfe, Blake and Ichter, Brian and Lu, Cewu and Xu, Charles and Le, Charlotte and Finn, Chelsea and Wang, Chen and Xu, Chenfeng and Chi, Cheng and Huang, Chenguang and Chan, Christine and Agia, Christopher and Pan, Chuer and Fu, Chuyuan and Devin, Coline and Xu, Danfei and Morton, Daniel and Driess, Danny and Chen, Daphne and Pathak, Deepak and Shah, Dhruv and Büchler, Dieter and Jayaraman, Dinesh and Kalashnikov, Dmitry and Sadigh, Dorsa and Johns, Edward and Foster, Ethan and Liu, Fangchen and Ceola, Federico and Xia, Fei and Zhao, Feiyu and Stulp, Freek and Zhou, Gaoyue and Sukhatme, Gaurav S. and Salhotra, Gautam and Yan, Ge and Feng, Gilbert and Schiavi, Giulio and Berseth, Glen and Kahn, Gregory and Wang, Guanzhi and Su, Hao and Fang, Hao-Shu and Shi, Haochen and Bao, Henghui and Ben Amor, Heni and Christensen, Henrik I and Furuta, Hiroki and Walke, Homer and Fang, Hongjie and Ha, Huy and Mordatch, Igor and Radosavovic, Ilija and Leal, Isabel and Liang, Jacky and Abou-Chakra, Jad and Kim, Jaehyung and Drake, Jaimyn and Peters, Jan and Schneider, Jan and Hsu, Jasmine and Bohg, Jeannette and Bingham, Jeffrey and Wu, Jeffrey and Gao, Jensen and Hu, Jiaheng and Wu, Jiajun and Wu, Jialin and Sun, Jiankai and Luo, Jianlan and Gu, Jiayuan and Tan, Jie and Oh, Jihoon and Wu, Jimmy and Lu, Jingpei and Yang, Jingyun and Malik, Jitendra and Silvério, João and Hejna, Joey and Booher, Jonathan and Tompson, Jonathan and Yang, Jonathan and Salvador, Jordi and Lim, Joseph J. and Han, Junhyek and Wang, Kaiyuan and Rao, Kanishka and Pertsch, Karl and Hausman, Karol and Go, Keegan and Gopalakrishnan, Keerthana and Goldberg, Ken and Byrne, Kendra and Oslund, Kenneth and Kawaharazuka, Kento and Black, Kevin and Lin, Kevin and Zhang, Kevin and Ehsani, Kiana and Lekkala, Kiran and Ellis, Kirsty and Rana, Krishan and Srinivasan, Krishnan and Fang, Kuan and Singh, Kunal Pratap and Zeng, Kuo-Hao and Hatch, Kyle and Hsu, Kyle and Itti, Laurent and Chen, Lawrence Yunliang and Pinto, Lerrel and Fei-Fei, Li and Tan, Liam and Fan, Linxi Jim and Ott, Lionel and Lee, Lisa and Weihs, Luca and Chen, Magnum and Lepert, Marion and Memmel, Marius and Tomizuka, Masayoshi and Itkina, Masha and Castro, Mateo Guaman and Spero, Max and Du, Maximilian and Ahn, Michael and Yip, Michael C. and Zhang, Mingtong and Ding, Mingyu and Heo, Minho and Srirama, Mohan Kumar and Sharma, Mohit and Kim, Moo Jin and Kanazawa, Naoaki and Hansen, Nicklas and Heess, Nicolas and Joshi, Nikhil J and Suenderhauf, Niko and Liu, Ning and Di Palo, Norman and Shafiullah, Nur Muhammad Mahi and Mees, Oier and Kroemer, Oliver and Bastani, Osbert and Sanketi, Pannag R and Miller, Patrick Tree and Yin, Patrick and Wohlhart, Paul and Xu, Peng and Fagan, Peter David and Mitrano, Peter and Sermanet, Pierre and Abbeel, Pieter and Sundaresan, Priya and Chen, Qiuyu and Vuong, Quan and Rafailov, Rafael and Tian, Ran and Doshi, Ria and Martín-Martín, Roberto and Baijal, Rohan and Scalise, Rosario and Hendrix, Rose and Lin, Roy and Qian, Runjia and Zhang, Ruohan and Mendonca, Russell and Shah, Rutav and Hoque, Ryan and Julian, Ryan and Bustamante, Samuel and Kirmani, Sean and Levine, Sergey and Lin, Shan and Moore, Sherry and Bahl, Shikhar and Dass, Shivin and Sonawani, Shubham and Song, Shuran and Xu, Sichun and Haldar, Siddhant and Karamcheti, Siddharth and Adebola, Simeon and Guist, Simon and Nasiriany, Soroush and Schaal, Stefan and Welker, Stefan and Tian, Stephen and Ramamoorthy, Subramanian and Dasari, Sudeep and Belkhale, Suneel and Park, Sungjae and Nair, Suraj and Mirchandani, Suvir and Osa, Takayuki and Gupta, Tanmay and Harada, Tatsuya and Matsushima, Tatsuya and Xiao, Ted and Kollar, Thomas and Yu, Tianhe and Ding, Tianli and Davchev, Todor and Zhao, Tony Z. and Armstrong, Travis and Darrell, Trevor and Chung, Trinity and Jain, Vidhi and Vanhoucke, Vincent and Zhan, Wei and Zhou, Wenxuan and Burgard, Wolfram and Chen, Xi and Wang, Xiaolong and Zhu, Xinghao and Geng, Xinyang and Liu, Xiyuan and Liangwei, Xu and Li, Xuanlin and Lu, Yao and Ma, Yecheng Jason and Kim, Yejin and Chebotar, Yevgen and Zhou, Yifan and Zhu, Yifeng and Wu, Yilin and Xu, Ying and Wang, Yixuan and Bisk, Yonatan and Cho, Yoonyoung and Lee, Youngwoon and Cui, Yuchen and Cao, Yue and Wu, Yueh-Hua and Tang, Yujin and Zhu, Yuke and Zhang, Yunchu and Jiang, Yunfan and Li, Yunshuang and Li, Yunzhu and Iwasawa, Yusuke and Matsuo, Yutaka and Ma, Zehan and Xu, Zhuo and Cui, Zichen Jeff and Zhang, Zichen and Lin, Zipeng},booktitle={Proc.~of the IEEE International Conference on Robotics \& Automation (ICRA)},year={2024},}
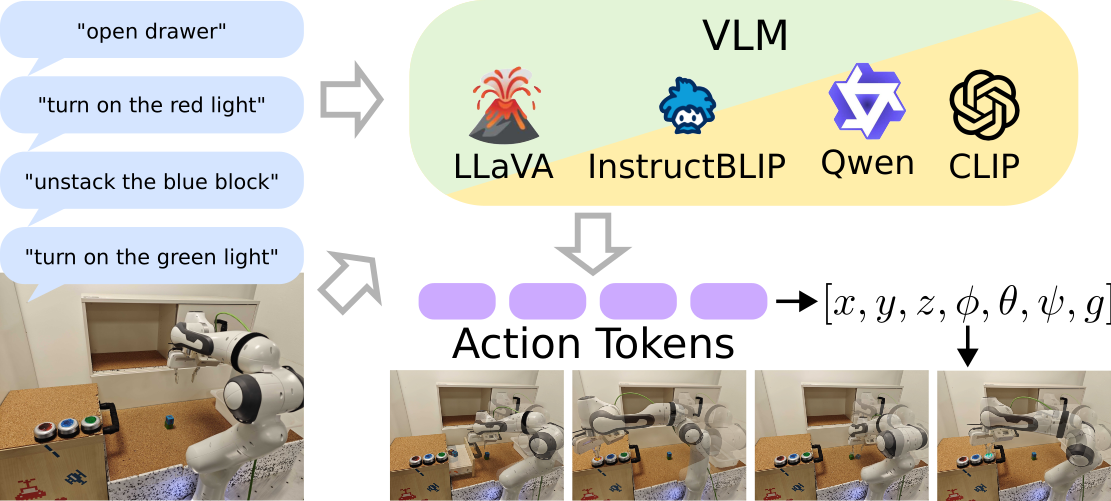
What Matters in Employing Vision Language Models for Tokenizing Actions in Robot Control?
Nicolai Dorka*, Chenguang Huang*, Tim Welschehold, and Wolfram Burgard
In First Workshop on Vision-Language Models for Navigation and Manipulation at ICRA, 2024
@inproceedings{dorka2024what,title={What Matters in Employing Vision Language Models for Tokenizing Actions in Robot Control?},author={Dorka, Nicolai and Huang, Chenguang and Welschehold, Tim and Burgard, Wolfram},booktitle={First Workshop on Vision-Language Models for Navigation and Manipulation at ICRA},year={2024},}
Hierarchical Open-Vocabulary 3D Scene Graphs for Language-Grounded Robot Navigation
Abdelrhman Werby*, Chenguang Huang*, Martin Büchner*, Abhinav Valada, and Wolfram Burgard
In Proc. of Robotics: Science and Systems (RSS), 2024
@inproceedings{werby2024hovsg,author={Werby, Abdelrhman and Huang, Chenguang and Büchner, Martin and Valada, Abhinav and Burgard, Wolfram},title={{Hierarchical Open-Vocabulary 3D Scene Graphs for Language-Grounded Robot Navigation}},booktitle={Proc.~of Robotics: Science and Systems (RSS)},year={2024},}
2023
Audio Visual Language Maps for Robot Navigation
Chenguang Huang, Oier Mees, Andy Zeng, and Wolfram Burgard
In Proc. of the International Symposium of Experimental Robotics (ISER), 2023
@inproceedings{huang23avlmaps,title={Audio Visual Language Maps for Robot Navigation},author={Huang, Chenguang and Mees, Oier and Zeng, Andy and Burgard, Wolfram},booktitle={Proc.~of the International Symposium of Experimental Robotics (ISER)},year={2023},}
Visual language maps for robot navigation
Chenguang Huang, Oier Mees, Andy Zeng, and Wolfram Burgard
In Proc. of the IEEE International Conference on Robotics & Automation (ICRA), 2023
@inproceedings{huang2023visual,title={Visual language maps for robot navigation},author={Huang, Chenguang and Mees, Oier and Zeng, Andy and Burgard, Wolfram},booktitle={Proc.~of the IEEE International Conference on Robotics \& Automation (ICRA)},year={2023},}